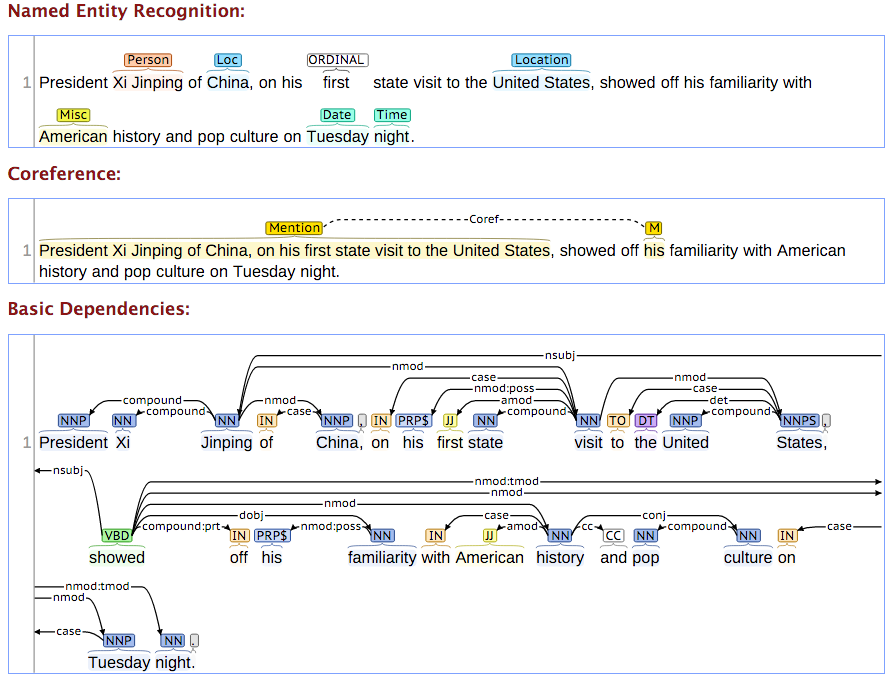
Pour compléter le tutoriel sur la détection de la langue d’un message, nous allons maintenant voir comment appliquer des traitements text mining avancés à un corpus, à l’aide de la librairie Stanford CoreNLP. Le groupe de recherche de l’université de Stanford partage depuis plusieurs années une série d’outils, parmi les meilleurs du marché, en Java, permettant notamment de découper efficacement son texte en tokens, d’identifier le type de mots (Part-of-speech ou PoS), d’entrainer des modèles à la détection d’entités nommées (NER) ou de lemmatiser un texte. La documentation de Stanford est particulièrement riche et explicite quant à la nature de ces traitements. Le principe général est simple. Nous allons déclarer un « pipeline » de traitements, qui sera exécuté pour chacun des textes du corpus, envoyés successivement. Par exemple, ce pipeline peut consister à découper le texte en phrases, puis en tokens, annoter les tokens avec leur PoS et enfin à lemmatiser les tokens.
Malheureusement, tous ces traitements ne sont pas disponibles pour toutes les langues, qui présentent chacune leurs spécificités. Aujourd’hui, je vous propose un tutoriel pour appliquer des traitements avancés sur un corpus de texte (lemmatisation, détection d’entités nommées, PoS Tagging), sans être un crack de java, et surtout en appliquant tous ces traitements à des textes courts et francophones.
fausse photo site de rencontre Les pré-requis : Télécharger les librairies nécessaires
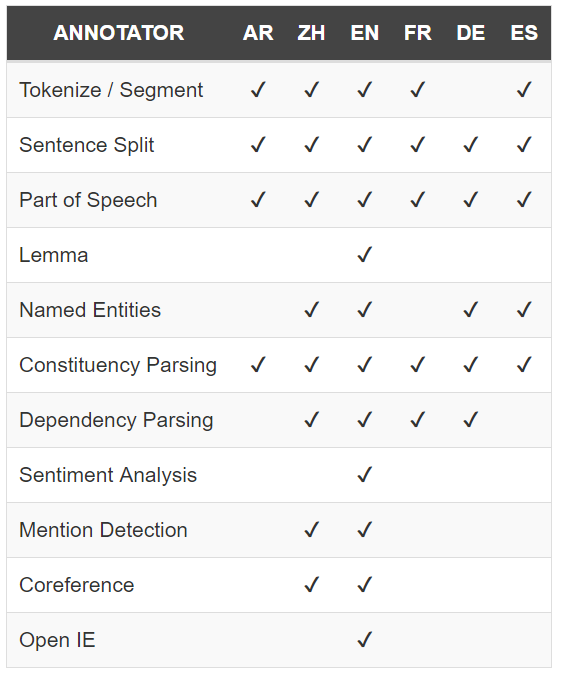
Pour réaliser ce tutoriel, votre machine doit disposer de :
> Java 1.8 et la dernière version de Talend installée (v. 6.4.1)
> Stanford CoreNLP et, a minima, le modèle français
> un lexique de formes, fichier délimité par des tabulations. Par exemple, le dictionnaire français d’iramuteq.
> un modèle de détection d’entités nommées, par exemple Europeana
> la librairie Commons Lang
menton petite annonce gay Le job Talend

http://syris.fr/?powtovuylust=sites-de-rencontre-totalement-gratuit-en-france&a5f=72 Première étape : Le chargement des librairies
Dans un premier temps, nous ajouter 3 composants tLibraryLoad afin d’importer les librairies nécessaires à l’exécution de notre script, et nous allons les relier par un lien de type « OnSubjobOk ». Une fois la première librairie chargée avec succès, on chargera la suivante, etc.
> commons.lang.3.7 : une librairie qui permet de manipuler plus simplement les chaines de caractères
> stanford-corenlp-3.7.0 : les outils Stanford
> stanford-french-corenlp-2016-10-31-models : le modèle pour les textes francophones
Deuxième étape : La déclaration d’un pipeline
En terme de performance, la longueur du texte importe peu sur la durée des traitements que nous allons réaliser, en revanche, le chargement systématique d’un pipeline peut-être très chronophage et consommateur de ressources. Dans notre exemple, tous les textes sont en français. Nous allons donc déclarer une bonne fois pour toutes un pipeline de traitements adapté à notre corpus. Pour cela, ajoutez un composant tJava et liez-le par un lien OnSubjobOk. Dans l’onglet « Paramètres simples » du composant, nous déclarons les propriétés du pipeline. N’hésitez pas à vous référer à la documentation de Stanford pour bien comprendre les propriétés du pipeline, plusieurs paramètres peuvent être ajustés selon le cas.
// On crée un objet Properties
Properties props_fr = new Properties();
// On définit les propriétés du pipeline : on annote, on tokenise, on découpe les phrases, on tague le type de mot, on lemmatise, on détecte les entités nommées
props_fr.put("annotators", "tokenize, ssplit, pos, custom.lemma,ner");
// on ajoute les propriétés nécessaires pour que les traitements s'appliquent au français
props_fr.setProperty("props_fr", "StanfordCoreNLP-french.properties");
props_fr.setProperty("parse.model","edu/stanford/nlp/models/lexparser/frenchFactored.ser.gz");
props_fr.setProperty("pos.model","edu/stanford/nlp/models/pos-tagger/french/french.tagger");
props_fr.setProperty("tokenize.language","French");
props_fr.setProperty("tokenize.options", "untokenizable=noneDelete");
props_fr.setProperty("tokenize.keepeol","false");// True = garde les sauts de ligne
props_fr.setProperty("tokenize.verbose","false"); // True = affiche les tokens
props_fr.setProperty("ssplit.newlineIsSentenceBreak", "always");
props_fr.setProperty("ner.model","C:/.../eunews.fr.crf.gz"); // précisez le chemin où se trouve le modèle de détection d'entités nommées Europeana
props_fr.setProperty("customAnnotatorClass.custom.lemma","routines.CustomLemmaAnnotator");
// déclaration du pipeline, en lui passant les propriétés
StanfordCoreNLP pipeline_fr = new StanfordCoreNLP(props_fr);
// on ajoute le pipeline en variable globale pour pouvoir l'appeler ultérieurement
globalMap.put("pipeline_fr",pipeline_fr);
Dans l’onglet « Paramètres avancés », nous importons les éléments nécessaires à l’exécution de nos futurs traitements :
import java.util.Properties; import java.util.ArrayList; import edu.stanford.nlp.pipeline.Annotation; import edu.stanford.nlp.pipeline.StanfordCoreNLP; import edu.stanford.nlp.ling.CoreAnnotations; import edu.stanford.nlp.ling.CoreAnnotations.NamedEntityTagAnnotation; import edu.stanford.nlp.ling.CoreAnnotations.PartOfSpeechAnnotation; import edu.stanford.nlp.ling.CoreAnnotations.SentencesAnnotation; import edu.stanford.nlp.ling.CoreAnnotations.TextAnnotation; import edu.stanford.nlp.ling.CoreAnnotations.TokensAnnotation; import edu.stanford.nlp.ling.CoreAnnotations.LemmaAnnotation; import edu.stanford.nlp.ling.CoreLabel; import edu.stanford.nlp.util.CoreMap; import edu.stanford.nlp.international.french.*;
Troisième étape : Ajouter un annotateur pour la lemmatisation
A l’étape précédente, nous avons précisé dans le pipeline que nous allions utiliser notre propre lemmatiseur. Puis, nous avons ajouté une propriété appelant ce lemmatiseur.
props_fr.put("annotators", "tokenize, ssplit, pos, custom.lemma,ner");
props_fr.setProperty("customAnnotatorClass.custom.lemma","routines.CustomLemmaAnnotator");
Pour créer cet annotateur, nous créons une routine sous Talend, nommée « CustomLemmaAnnotator ». La documentation de Stanford CoreNLP fourni toutes les informations sur la création de ce nouvel annotateur.

Voici le code adapté à Talend, il suffit simplement de paramétrer le chemin où se trouve votre lexique :
package routines;
import edu.stanford.nlp.ling.*;
import edu.stanford.nlp.pipeline.*;
import edu.stanford.nlp.io.*;
import edu.stanford.nlp.util.ArraySet;
import java.util.*;
final class CustomLemmaAnnotator implements Annotator {
HashMap<String,String> wordToLemma = new HashMap<String,String>();
public CustomLemmaAnnotator(String name, Properties props) {
// format should be tsv with word and lemma
String lemmaFile = new String("C:/.../lexique.txt");
List<String> lemmaEntries = IOUtils.linesFromFile(lemmaFile);
for (String lemmaEntry : lemmaEntries) {
wordToLemma.put(lemmaEntry.split("\\t")[0], lemmaEntry.split("\\t")[1]);
}
}
public void annotate(Annotation annotation) {
for (CoreLabel token : annotation.get(CoreAnnotations.TokensAnnotation.class)) {
String lemma = wordToLemma.getOrDefault(token.word(), token.word());
token.set(CoreAnnotations.LemmaAnnotation.class, lemma);
}
}
@Override
public Set<Class<? extends CoreAnnotation>> requires() {
return Collections.unmodifiableSet(new ArraySet<>(Arrays.asList(
CoreAnnotations.TextAnnotation.class,
CoreAnnotations.TokensAnnotation.class,
CoreAnnotations.SentencesAnnotation.class,
CoreAnnotations.PartOfSpeechAnnotation.class
)));
}
@Override
public Set<Class<? extends CoreAnnotation>> requirementsSatisfied() {
return Collections.singleton(CoreAnnotations.LemmaAnnotation.class);
}
}
Quatrième étape : Charger notre corpus ligne par ligne
Mon corpus est contenu dans un fichier csv, séparé par des points virgules, et contient deux colonnes : un id et un texte.

Pour charger ce fichier, j’utilise un composant tFileInputDelimited. Il ne reste plus qu’à préciser le chemin du fichier, le séparateur, la ligne d’en-tête, et l’encodage UTF-8 (dans les paramètres avancés).

Pour lire le fichier ligne par ligne, j’utilise un composant tFlowToIterate. En entrée, ce composant sera relié au tFileInputDelimited par un lien « main ». En sortie, tFlowToIterate sera lié à un composant tJava par un lien « iterate ». Je configure mes variables id et text, qui seront passées au composant suivant.

Cinquième étape : Implémenter les outils Stanford CoreNLP
Maintenant que le corpus est chargé, nous allons transmettre chaque texte à un script Java qui implémente les traitements Stanford CoreNLP.
// Déclaration du pipeline
StanfordCoreNLP pipeline_fr = ((StanfordCoreNLP)globalMap.get("pipeline_fr"));
// Récupération des variables du job précédent
String id=((String)globalMap.get("id"));
String text=((String)globalMap.get("text"));
// déclarations des variables de résultat
ArrayList<String> results_words = new ArrayList<>();
ArrayList<String> results_pos = new ArrayList<>();
ArrayList<String> results_person = new ArrayList<>();
ArrayList<String> results_organization = new ArrayList<>();
ArrayList<String> results_location = new ArrayList<>();
ArrayList<String> results_lemma = new ArrayList<>();
ArrayList<String> results_misc = new ArrayList<>();
// On crée un objet Annotation en lui passant le texte, puis on appelle la fonction
Annotation document = new Annotation(text);
pipeline_fr.annotate(document);
// Il y a plusieurs phrases dans chaque document.
// On va parcourir successivement les phrases et les mots (token) qu'elles contiennent
List<CoreMap> sentences = document.get(SentencesAnnotation.class);
for(CoreMap sentence: sentences) {
for (CoreLabel token: sentence.get(TokensAnnotation.class)) {
// On récupère chaque token, on le réduit en minuscules
String word = StringHandling.DOWNCASE(token.get(TextAnnotation.class));
String lemma ="";
// L'annotation est parfois hasardeuse en français. On vérifie qu'il ne s'agit pas de ponctuation
if ((StringUtils.containsAny(word,"\\.?,;!*)(&#}{][>@/")==false) && word.length()>1){
// S'il s'agit bien d'un mot, on récupère son type (PoS)
String pos = token.get(PartOfSpeechAnnotation.class);
// tous les types de mots ne nous intéressent pas.
// On ne conserve que les noms, verbes, adjectifs. On filtre les déterminants, les prépositions, etc...
if (!(pos.equals("PUNC") || pos.equals("DET") || pos.equals("DET") || pos.equals("P") || pos.equals("CC") || pos.equals("PROREL")||
pos.equals("PRO")|| pos.equals("CLS")|| pos.equals("ADV") || pos.equals("CS") || pos.equals("PROWH")|| pos.equals("CLO")|| pos.equals("CL")|| pos.equals("CLR")
|| pos.equals("C")|| lemma.equals("être")|| lemma.equals("avoir")))
{
// On récupère le lemme (la forme canonique du terme. Ex : le verbe à l'infinitif, le nom au singulier masculin...)
lemma = token.get(LemmaAnnotation.class);
lemma=StringHandling.DOWNCASE(lemma);
// on stocke le mot, son type et son lemme, dans nos variables de résultat
results_words.add(word);
results_pos.add(pos);
results_lemma.add(lemma);
// On récupère les entités nommées (entreprise, personne...)
String ner = token.get(NamedEntityTagAnnotation.class);
// s'il s'agit bien d'une entité nommée, on stocke le résultat dans la bonne variable
if (!(ner.equals("O")) ) {
// une personne
if(ner.equals("I-PERS")) {
results_person.add(word);
}
// une organisation
else if (ner.equals("I-ORG")) {
results_organization.add(word);
}
// un lieu
else if (ner.equals("I-LIEU")) {
results_location.add(word);
}
// le reste
else {
results_misc.add(word);
}
} else {
System.out.println("pas d'entité détecté");
}
}
}
}
}
// on transmet les résultats au composant suivant
row2.id=((String)globalMap.get("id"));;
row2.text=((String)globalMap.get("text"));
row2.results_words = results_words;
row2.results_pos = results_pos;
row2.results_lemma=results_lemma;
row2.results_person = results_person;
row2.results_organization = results_organization;
row2.results_location = results_location;
row2.results_misc=results_misc;
Dernière étape : Sauvegarder les résultats
A l’aide d’un composant tFileOutputDelimited, cette fois-ci je vais sauvegarder mes résultats dans un fichier csv. Pour cela, je clique sur « Modifier le schéma » et je précise la nature de mes colonnes. Je paramètre le chemin de destination du fichier, le délimiteur, l’encodage UTF-8 (dans les paramètres avancés), etc. Et surtout, je coche la case « Ecrire après ». En effet, puisqu’on envoie les textes les uns après les autres, il est nécessaire d’écrire chaque ligne de résultat à la suite des autres, de manière à ne pas écraser les résultats !
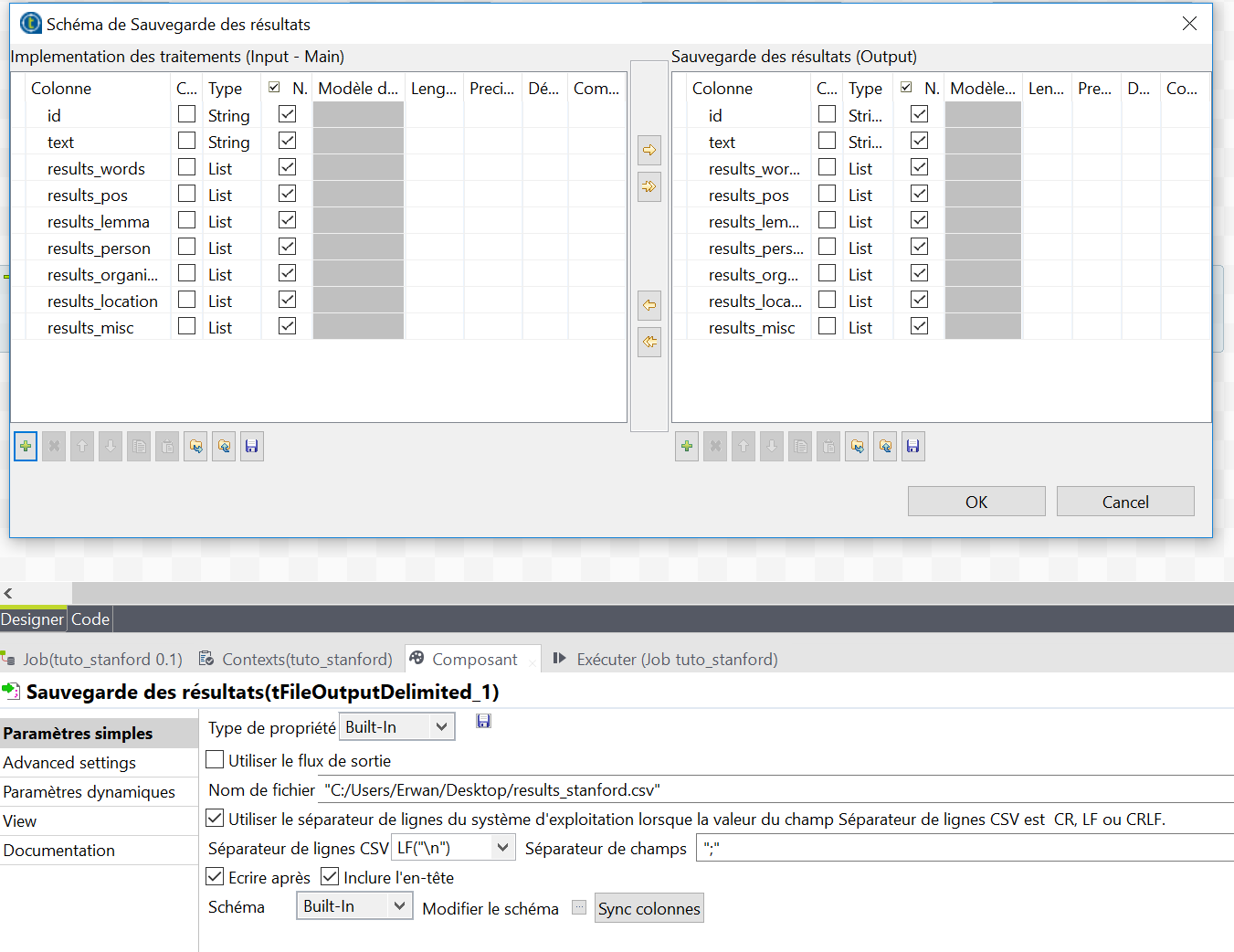
Le résultat
Le résultat est assez bluffant, y compris sur des textes courts, issus des réseaux sociaux, et offre des possibilités d’exploitation intéressantes en statistiques descriptives :
> on dispose d’une colonne de lemmes (results_lemmas) où les mots ont été réduits à leurs formes canoniques (singulier, infinitif, masculin, …) tant qu’ils sont présents dans notre lexique
> un colonne avec le Part-of-Speech (results_pos) permettant de filtrer certains termes ou bien de calculer des densités (de verbes, de noms…)
> quatre colonnes avec les entités nommées par type

J’espère que ce tutoriel vous aura éclairé sur les usages potentiels (il y en a d’autres !) de Stanford CoreNLP. N’hésitez pas à partager vos retours d’expériences car il y a très peu de tutoriels sur le sujet, notamment sur le traitement de langues autres que l’anglais !