Twitter est le site de contenus le plus fréquemment mis à jour ; environ 500 millions de messages sont postés quotidiennement sur sa plateforme. Dans un précédent billet, je me suis intéressé de près à la valeur de Twitter, en tant que moteur de recommandation ou pour la recherche de marché, d’autant plus que Twitter met à disposition des développeurs des APIs publiques, simples d’utilisation. Aujourd’hui, je vous propose de mettre en œuvre concrètement, la collecte, le traitement et l’analyse de tweets sans savoir coder.
Pour cela, nous allons procéder en plusieurs étapes :
1. déclarer une application Twitter pour pouvoir s’authentifier à la plateforme.
2. construire une procédure avec Talend qui collecte
3. formater les données pour que le dataset soit uniforme et structuré
4. enregistrer les données au format Excel pour pouvoir les exploiter facilement par la suite.
Avant de démarrer, rappelons la définition d’une API et faisons un rapide tour d’horizon des APIs publiques de Twitter.
1. L’API Twitter en résumé
Une API, ou application programming interface, est une série de méthodes mise à disposition par un site à des développeurs tiers, leur permettant d’utiliser certaines fonctionnalités ou d’accéder à des données du site. Pour illustrer cette définition d’un exemple simple, depuis le site LeMonde.fr vous pouvez partager un article en cliquant sur un bouton mis à disposition par Twitter.
Twitter dispose de plusieurs APIs permettant de requêter sa base de données, mais aussi de construire des services au-dessus de sa plateforme. Ces APIs sont particulièrement riches en retournant presque une centaine de variables par requête ; les données concernent les tweets (date de publication, le texte du message, etc.), l’auteur (date de création du compte, pseudo…), les entités contenus dans les messages (hashtags, mentions, urls…) et des informations de localisation (pays, timezone, longitude / latitude).
Pour faire simple, deux APIs nous intéressent particulièrement pour ce tutoriel :
– l’API REST 1.1 retourne des données historiques. La réponse à une requête ressemble plus ou moins à ce que l’on obtiendrait en tapant un mot clé dans le moteur de recherche de Twitter. Le nombre de requêtes est limité à 450 demandes toutes les 15 min.
– L’API Streaming fonctionne comme un enregistreur. L’API ne renvoie pas de données historiques, mais une fois la requête mise en place on récupèrera l’ensemble des messages répondant à cette requête. La limite de l’API est difficilement atteignable, il faudrait atteindre un volume équivalent à 1% des messages publiés sur Twitter à un instant t.
Les APIs retournent les résultats d’une requête dans un format brut (JSON), qu’il va falloir transformer pour rendre les données manipulables dans n’importe quelle interface de visualisation (Excel, Google Fusion Table, Tableau Software…)
2. Créer une application Twitter
La première étape est un prérequis consistant à obtenir des identifiants permettant de se connecter aux APIs de Twitter. De nombreux tutoriels en ligne expliquent comment créer une application ; une recherche Google vous fournira toutes les réponses nécessaires si vous rencontrez des difficultés lors de la configuration. Je ne m’attache qu’à décrire les étapes essentielles :
– Rendez-vous sur https://apps.twitter.com/
– Cliquez sur « Create new app » pour démarrer la configuration d’une application
– Donnez un nom à cette application et remplissez les champs essentiels
– Rendez-vous dans le 3e onglet, « Keys and access tokens »
– En bas de page, cliquez sur « Create my access token »
Désormais, vous disposez de quatre paramètres essentiels, présentés sur ce tableau de bord : une clé d’accès à l’API et un jeton d’accès. Il s’agit respectivement des champs consumer key / consumer secret et access token / access token secret.
3. Installer et configurer Talend
Nous allons utiliser un logiciel Open Source pour construire la requête aux APIs et transformer les données brutes qui nous seront renvoyées. Pour cela, commencez par télécharger et installer Talend Open Studio for Big Data.
Talend fonctionne dans un environnement Java et il vous faudra installer le kit de développement (JDK) suivant.
Nous allons ajouter un composant complémentaire, développé par Gabriele Baldasarre, nous fournissant les outils essentiels pour construire notre requête. Téléchargez-le ici. Décompressez le fichier dans le dossier de votre choix. Ce dossier vous servira de librairie pour installer des composants complémentaires.
Démarrez le logiciel, créez un nouveau projet et rendez-vous dans les préférences de Talend (Menu > Fenêtres > Préférences). Cherchez la rubrique « composants » dans l’arborescence (Talend > composants). Indiquez le chemin vers le dossier contenant le composant.
Vérifiez que le composant est bien installé en effectuant une recherche dans votre Palette (à droite). En tapant « twitter », vous devriez trouver 3 composants :
– tTwitterOAuth : permet de s’authentifier à Twitter
– tTwitterInput : permet de construire une requête à l’API Rest 1.1
– tTwitterOAuthClose : permet de se déconnecter de Twitter
– tTwitterStreamInput : permet de construire une requête à l’API Streaming
4. Collecter les tweets
http://framatech.fr/?yspex=s%C3%A8vres-rencontre-x&5d8=fc > Déclarer des variables de contexte
Dans un premier temps, nous allons entreposer les clés APIs fournies par Twitter pour ne pas avoir à les copier/coller à chaque nouveau programme. A gauche de l’interface, cliquez bouton droit pour « créer un groupe de contexte », donnez-lui un nom. Validez.
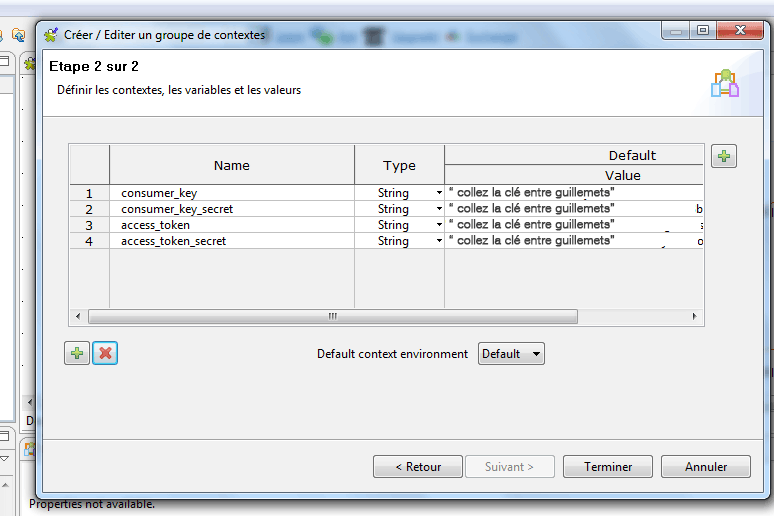
Cliquez sur la croix verte pour déclarer une nouvelle variable de contexte. Nous allons déclarer 4 variables correspondant aux clés fournies par Twitter. Donnez un nom à la première variable (ex : consumer_key), attribuez lui un format (en l’occurrence « String », c’est-à-dire une chaine de caractères) et copier/coller la clé en la plaçant entre double quote.
pacé homme recherche > Construire le job Talend qui va collecter les messages
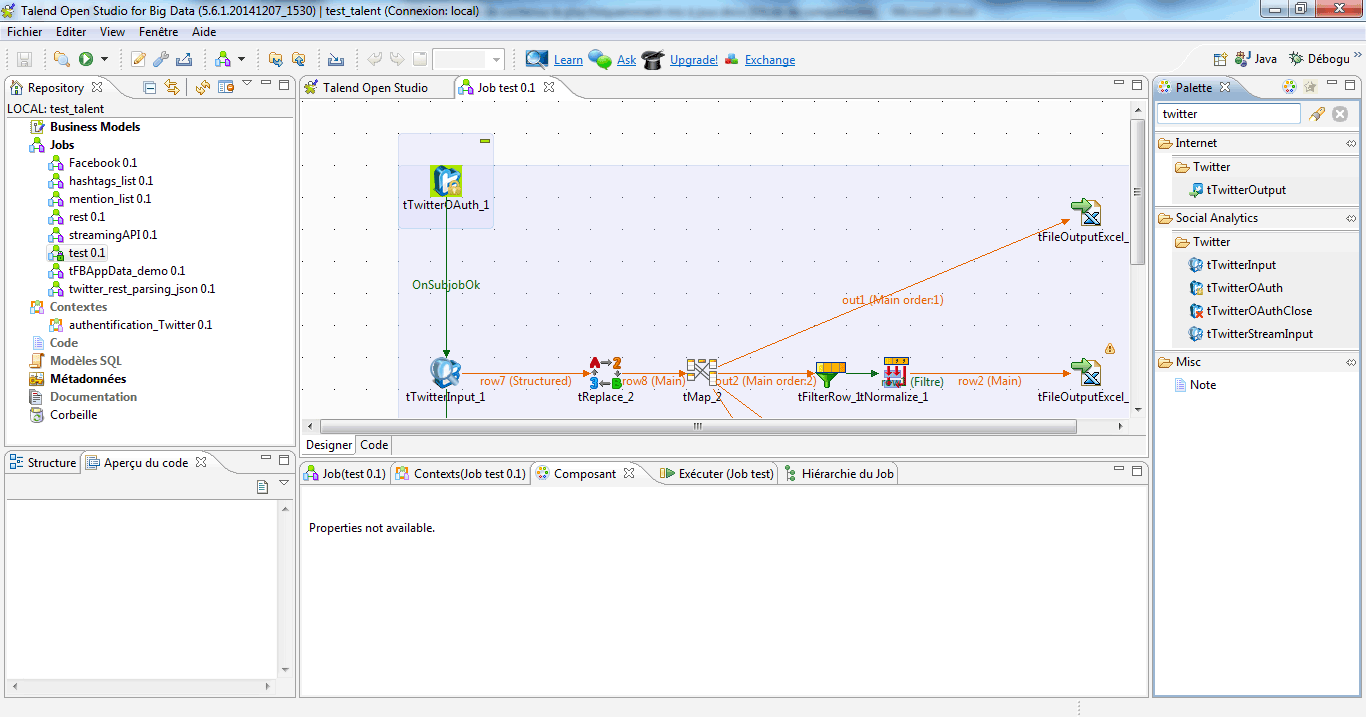
Pour collecter des Tweets, la procédure que nous allons construire correspondra au schéma suivant : on s’authentifie à Twitter, on envoie une requête, on se déconnecte.
Depuis votre palette (à droite), glissez-déposez les composants requis dans l’espace de développement. On placera les éléments de manière verticale pour rendre lisible la procédure. tTwitterOAuth, puis tTwitterInput, puis tTwitterOAuthClose.
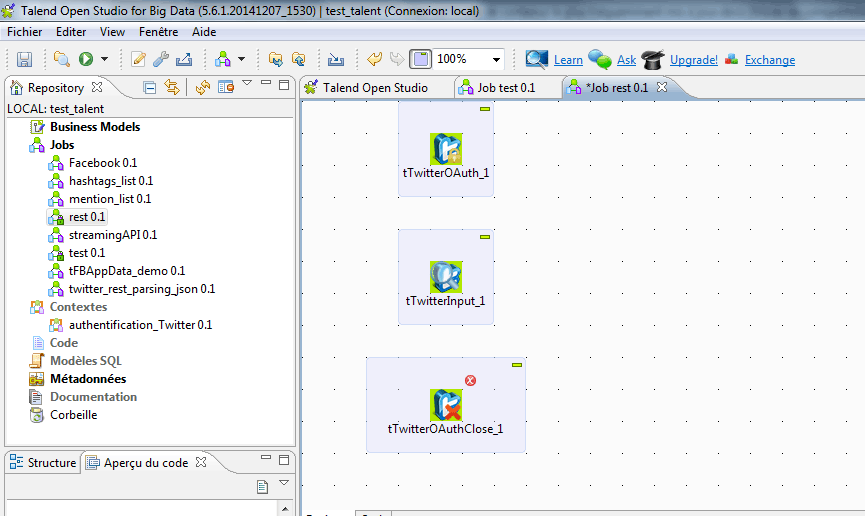
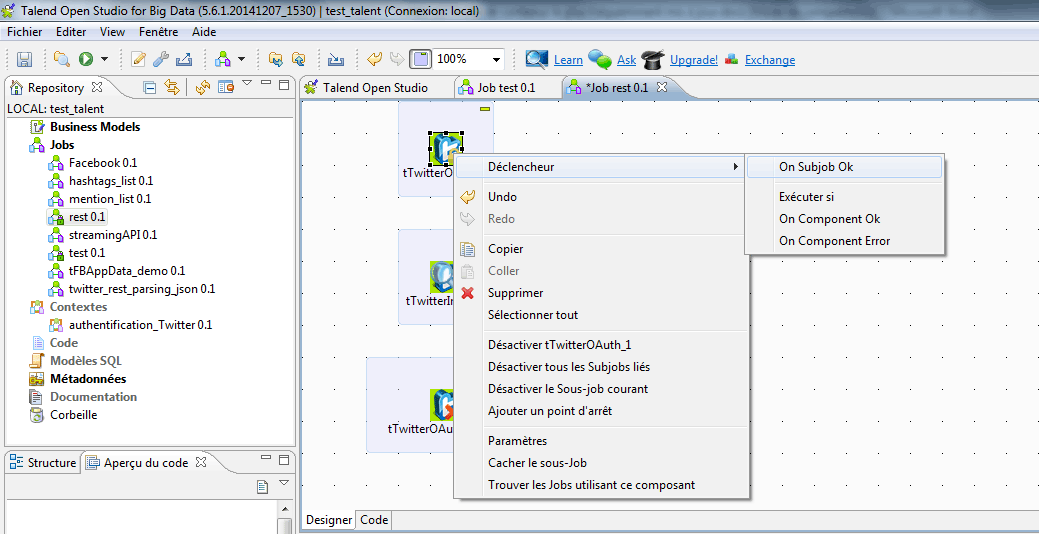
Liez les trois composants, en cliquant bouton droit sur chacun d’entre eux, puis en sélectionnant comme déclencheur « On Subjob OK ». Etirez la flèche jusqu’au composant suivant. Si les conditions requises sont respectées, les traitements passeront à l’étape suivante.
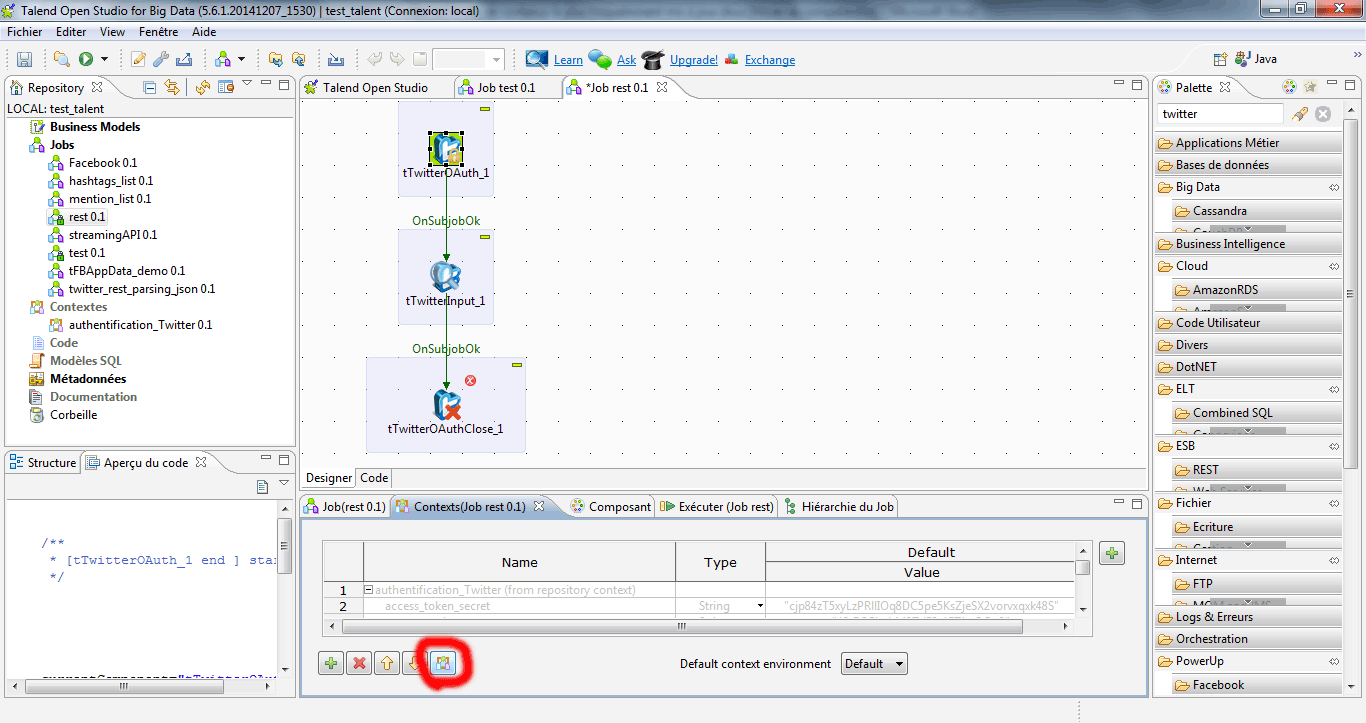
Kolomyagi > Configurer le composant d’authentification
Double cliquez sur le composant tTwitterOAuth. Dans l’onglet « Contexts », sélectionnez votre groupe de contexte en utilisant l’icône destiné à cet effet.
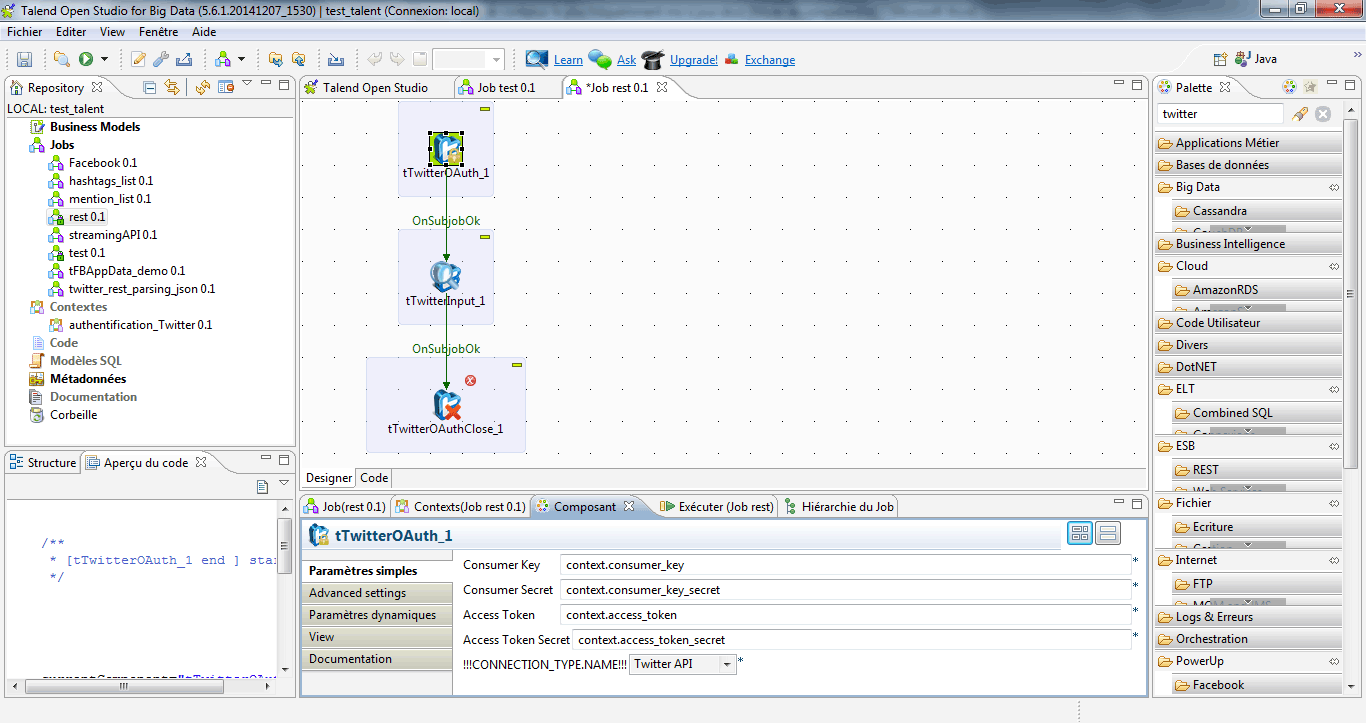
Dans les paramètres simples de l’onglet « Composant », indiquez vos variables de contexte avec le préfixe context.mavariable
> Définir la requête
Nous allons volontairement définir une requête un peu complexe. Celle-ci nous permettra de construire 4 fichiers contenant respectivement :
– une table des derniers tweets contenant un mot-clé avec les données associées aux messages et aux auteurs
– 3 listes avec respectivement les hashtags, les mentions et les URLs contenues dans les messages
D’abord, nous devons indiquer quels champs de l’API doivent nous être retournés lors de nos appels. Double cliquez sur le composant tTwitterInput. Dans l’onglet « Composant », cliquez sur « éditer le schéma ». Créez 12 variables, en veillant à leur attribuer le bon format (String, Long ou Booléen) comme présenté ci-dessous :
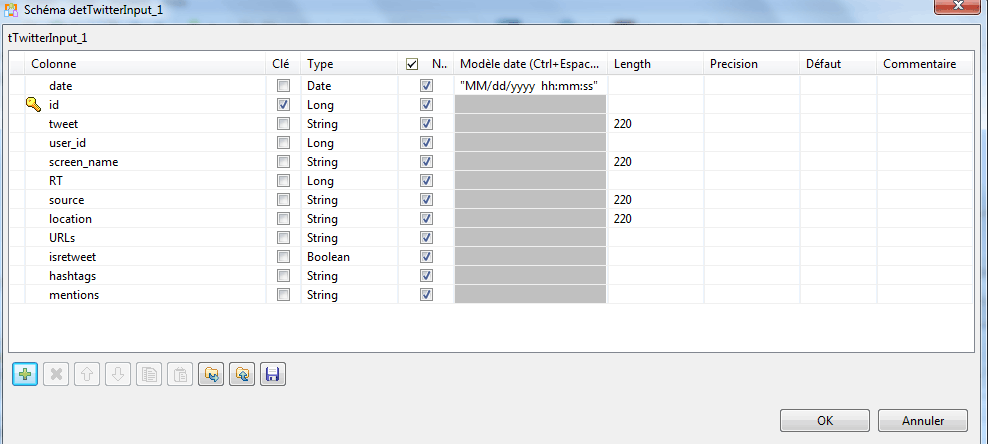
Ensuite, nous allons attribuer une opération à chacune des variables. C’est-à-dire que nous allons indiquer quel contenu doit être incrémenté dans chacune des variables (= bien associer une date dans la variable « date »). Remplissez le tableau comme présenté ci-dessous :
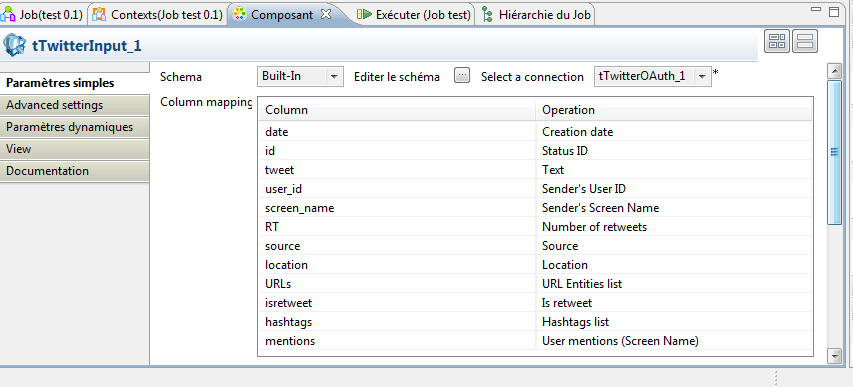
Nous allons maintenant définir le cœur de la requête. Pour cela, le composant permet de lister des mots-clés (de plein texte, mentions ou hashtags) et d’établir des conditions. Ici, nous allons collecter des messages qui incluent le hashtag #MWC15 ou la chaine de caractère « mobile world congress ». N’oubliez pas d’inscrire vos mots-clés entre double quotes.
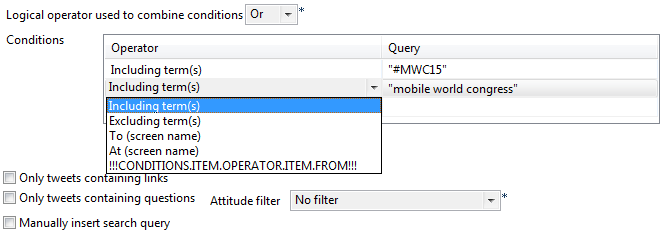
Dans les paramètres avancés, vous pouvez ajouter d’autres conditions. Je vous invite à jouer notamment avec la limite de requête. Dans le scénario de ce tutoriel, vous pouvez monter jusqu’à 17.999 messages. Néanmoins, restreignez votre requête tant que vous ne l’avez pas testée… Décochez l’option « Prefix entities with reserved characters ».
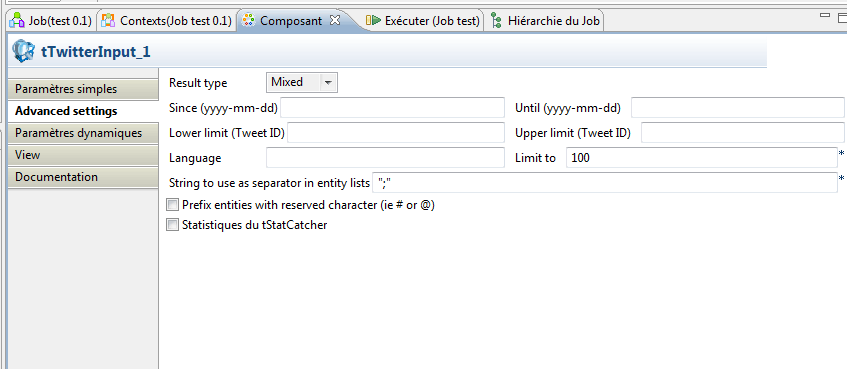
Testez votre job en cliquant sur le bouton « Play ».
5. Traiter et exporter les données
L’étape suivante consiste à inscrire les données dans plusieurs fichiers Excel, en les rendant manipulables. Comme indiqué précédemment, nous allons chercher à obtenir 4 fichiers en sortie :
– un fichier sous forme de tableau de bord contenant les tweets
– un fichier sous forme de liste contenant les hashtags contenus dans les tweets
– un fichier sous forme de liste contenant les mentions citées dans les tweets
– un fichier sous forme de liste contenant les URLs contenues dans les tweets
Nous ne pouvons pas bêtement inscrire les résultats brut retournés par l’API dans un fichier Excel, pour plusieurs raisons :
– Twitter renvoie ces résultats bruts au format JSON. Ce fichier est structuré sous forme de couples champs/valeurs que nous allons devoir « découper » pour construire un tableau composé de lignes et de colonnes. Heureusement le composant tTwitterInput nous facilite la tâche en structurant partiellement les données.
– Certains champs contiennent des caractères non-adaptés au stockage sous Excel. Ex : les tweets peuvent contenir des sauts de lignes qui viendraient briser l’uniformité de notre tableau final. De même, le champ « source » contient des balises HTML qu’il faudra à supprimer.
– Certains champs peuvent être retournés vides. Ex : Si un tweet ne contient pas de hashtags, le champ correspondant sera vide. Il faudra supprimer les lignes vides. A l’inverse, si un tweet contient plusieurs hashtags, Twitter nous renverra la donnée sous forme d’un tableau [hashtag1, hashtag2, hashtag3] qu’il faudra découper.
– Certains champs doivent être traités pour être rendus compréhensibles lors de l’analyse. Ex : Twitter retourne les données de géolocalisaton sous la forme d’un tableau [latitude,longitude]. Il faudra donc redécouper ce tableau.
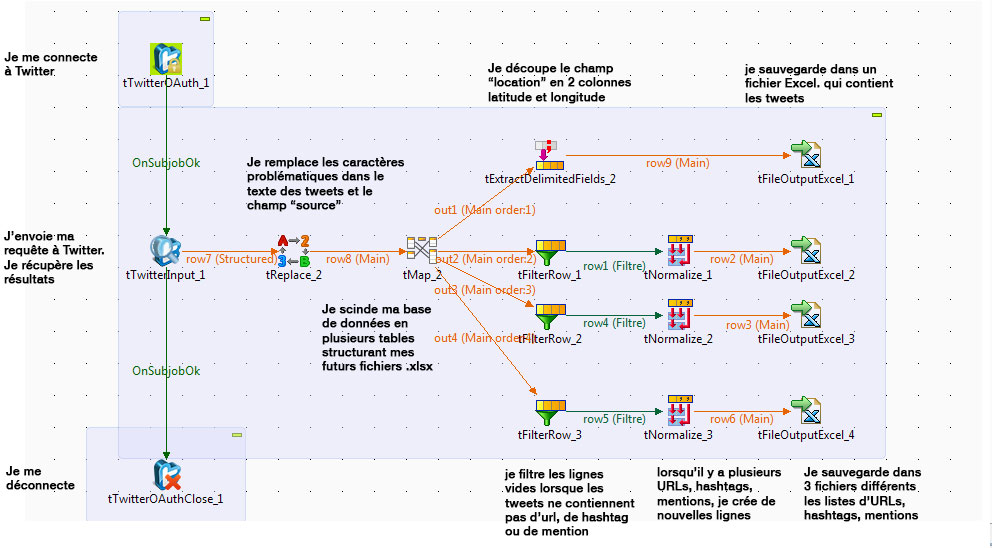
Nous allons procéder en plusieurs étapes à l’aide de différents composants :
– tReplace pour remplacer tous les sauts de lignes contenus dans le corps des tweets par des espaces. En effet, certains tweets contiennent des retours à la ligne et si nous ne les supprimons pas, la structure de notre tableau en sortie ne sera pas respectée.
– tMap pour construire la structure de nos tableaux dans chacun de nos fichiers Excel
– tFilterRow nous servira à supprimer les lignes vides. En effet, certains tweets ne contiennent pas de hashtags, d’url ou de mentions ; nous aurons donc des lignes vides dans notre tableau qu’il faudra supprimer.
– tExtractDelimitedFields nous sera utile pour découper le champ « location ». Ce champ retourne un tableau [latitude,longitude] qu’il faut éclater en 2 colonnes, l’une pour la latitude, l’autre pour la longitude.
– tNormalize pour normaliser les listes de hashtags, de mentions ou d’urls. Certains tweets peuvent contenir plusieurs hashtags. Twitter nous renverra alors une liste de hashtags séparés par des ‘ ;’ Nous allons créer de nouvelles lignes dans notre tableau pour les stocker les uns à la suite des autres.
Pour rendre lisible notre job, nous allons placer ces traitements de manière horizontale, de gauche à droite, sur notre espace de travail.
> Remplacer les caractères indésirables
Glissez-déposez le composant tReplace depuis la palette. Liez-le au composant tTwitterInput. Pour cela, cliquez bouton droit sur le composant tTwitterInput et choisissez « Row » puis « Structured ». Ainsi, le premier composant va transmettre des données partiellement structurées à tReplace.
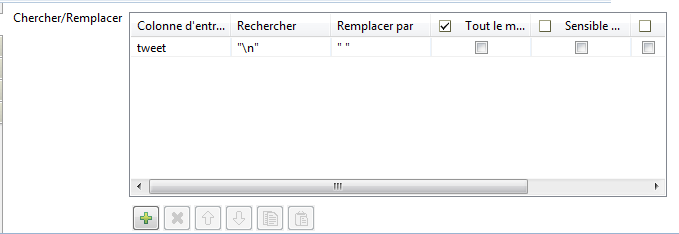
Double cliquez sur tReplace. Dans l’onglet « Composant », ajoutez une condition : sélectionnez le champ « tweet », recherchez les sauts de lignes en précisant entre double quotes ‘’\n’’ et remplacez-les par des espaces.
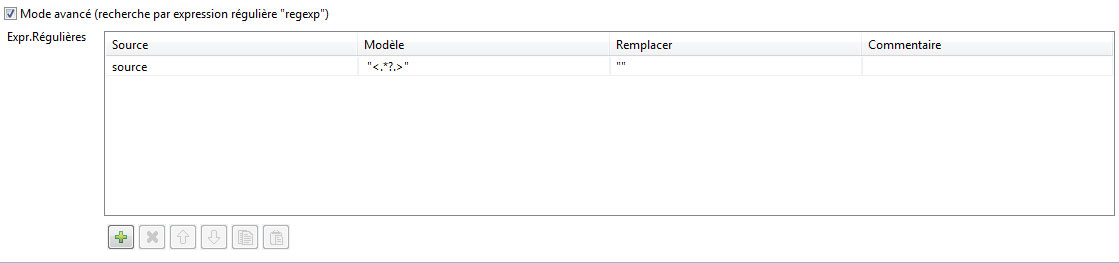
Plus bas, cochez la case « mode avancé » et entrez l’expression régulière « <.*?.> » qui nous permettra de supprimer toutes les balises HTML contenus dans le champ « source ».
> Construire le schéma de la base de données
Nous allons maintenant dispatcher les données collectées en construisant différentes tables, qui correspondront chacune à un fichier Excel. Pour cela, glissez-déposez le composant tMap sur l’espace de travail. Liez tReplace à ce composant en cliquant bouton droit puis en sélectionnant Row > Main.
Double-cliquez sur le composant tMap. Depuis l’onglet « Composant », cliquez sur « Editer le mapping ». A gauche de l’écran, vous visualisez votre table actuelle. A droite, nous allons créer 4 tables correspondant aux données que nous souhaiterons visualiser dans nos 4 fichiers Excel.
– out1 = table contenant les tweets et les données associées au message et à l’auteur
– out2 = table contenant la liste de urls publiées
– out3 = table contenant la liste des hashtags contenus dans les tweets
– out4 = table contenant la liste des mentions citées dans les tweets
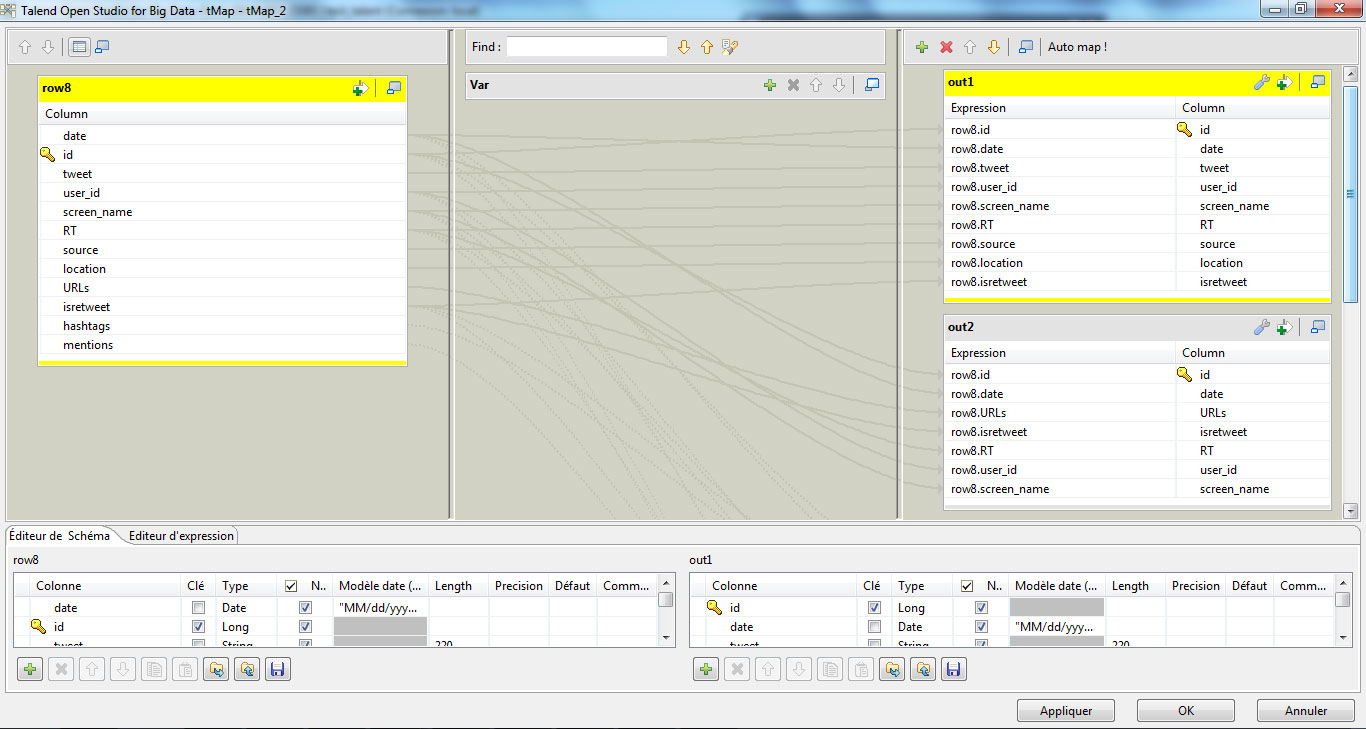
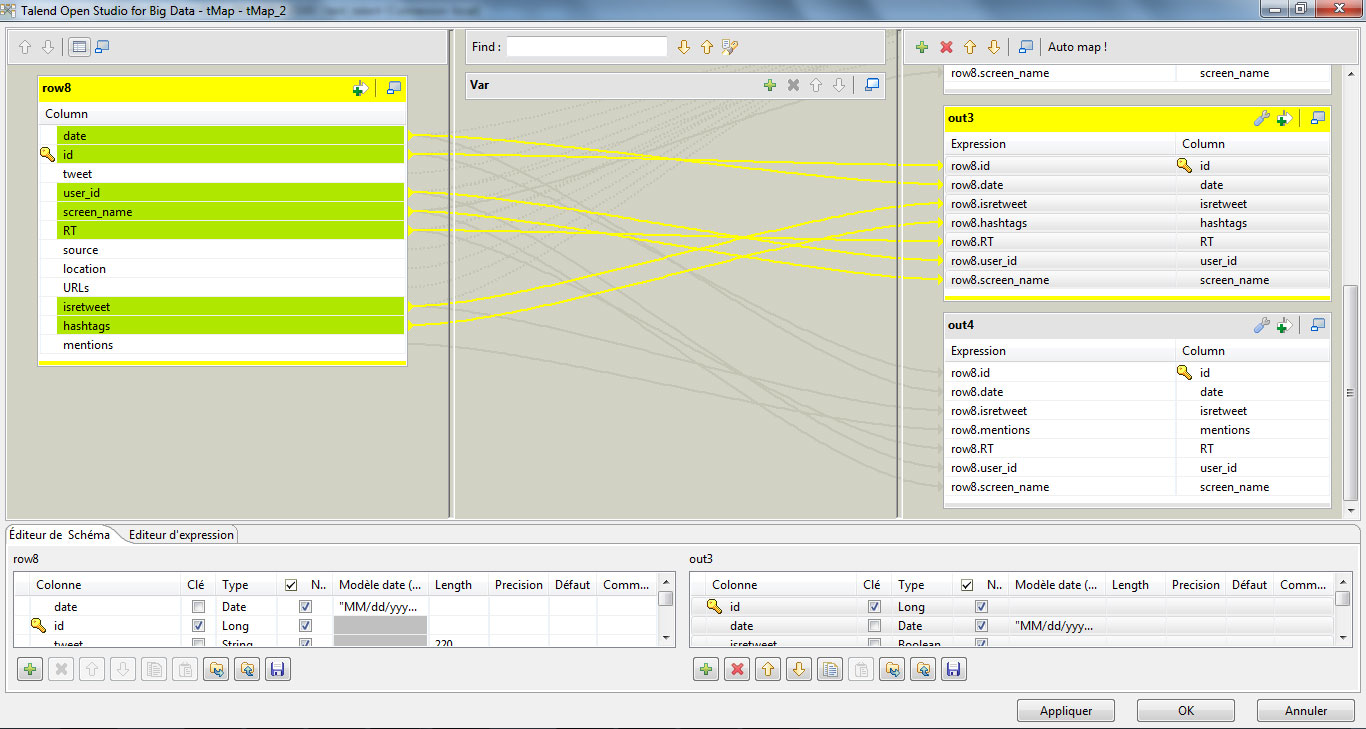
Créez quatre tables à l’aide de l’icône ‘+’ en haut à droite de l’écran, et glisser-déposer les champs comme présenté ci-dessus.
> Scinder en deux colonnes les données retournées par le champ « location »
Le champ « location », contenant les données de géolocalisation des utilisateurs acceptant de partager ses informations, renvoie un tableau au format [latitude; longitude], où chaque variable est une chaine de caractères. Dans notre schéma actuel, nous disposons d’une seule colonne entreposant ces données. Nous allons ajouter 2 nouvelles colonnes pour stocker chaque chaine de caractères.
Pour cela, nous allons utiliser le composant tExtractDelimitedFields. Depuis votre palette, glissez-déposez le composant sur l’espace de travail et liez-le avec le composant tMap. Cliquez bouton droit sur tMap et sélectionnez row > out1. Cela signifie que nous transmettons au composant tExtractDelimitedFields la table ‘out1’ contenant les champs que l’on souhaitera retrouver dans notre tableau de bord de tweets.
Depuis l’onglet « Composants », sélectionnez le champ « location » et indiquez le caractère séparateur des informations (un point virgule) entre double quotes.

Puis, cliquez sur « éditer le schéma » et ajoutez deux nouvelles colonnes, latitude et longitude, associées au format « String » (=chaine de caractères).
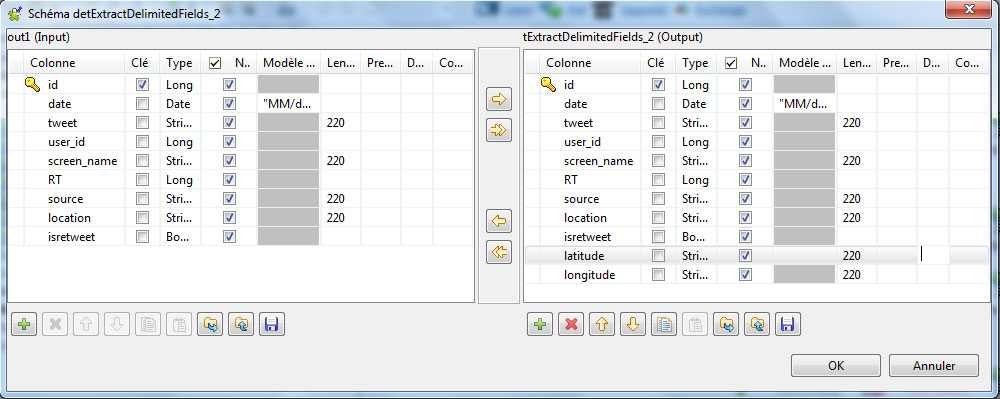
> Extraire la table des tweets
Nous avons accompli tous les traitements pour inscrire la première table dans un fichier Excel. Recherchez le composant « tFileOutputExcel » dans votre palette, placez-le dans votre espace de travail.
Cliquez bouton droit sur le composant tMap et liez-le au composant tFileOutputExcel en sélection row > out1. Ainsi, on envoie les données de la table out1 dans un fichier Excel.
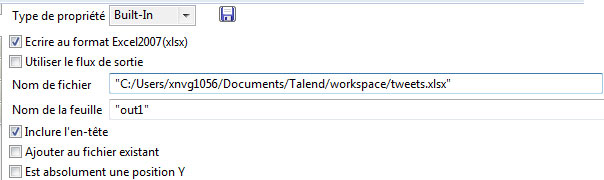
Double cliquez sur le composant tFileOutputExcel et précisez le chemin d’accès au fichier Excel dans lequel vous souhaitez inscrire les données. Vous pouvez cocher les cases « inscrire au format xlsx » pour bénéficier d’un plus grand format de tableur et « insérer les entêtes » pour inscrire un intitulé pour chaque colonne, ce qui facilitera les traitements ultérieurs.
Testez votre job en cliquant sur le bouton « Play » avant de passer à la suite.
> Constituer les listes de hashtags, d’urls et de mentions
Maintenant, nous allons écrire trois fichiers constituant des listes de hashtags, d’URLs et de mentions contenus dans les tweets. La méthode étant un peu rébarbative, nous allons décrire comment constituer la liste de hashtags.
A l’issue du mapping (tMap), nous devons filtrer les lignes vides contenus dans notre table. En effet, certains tweets ne contiennent parfois pas de hashtags. Glissez-déposez le composant « tFilterRow » et liez-le au tMap en sélectionnant Row > out3. Configurez le composant en introduisant une condition : les lignes qui contiennent des chaines de caractères d’une longueur égale à zéro sont supprimées.
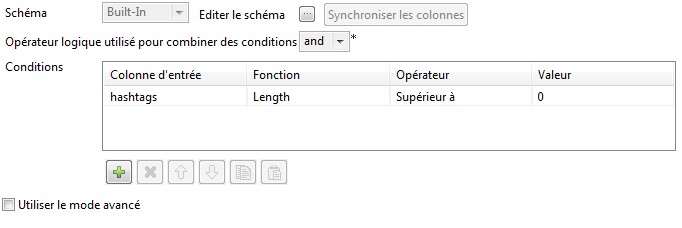
Inversement, certains tweets peuvent contenir plusieurs hashtags. Twitter renvoie alors une liste de hashtags séparés par un point virgule. Dans ce cas, nous allons créer de nouvelles lignes à la suite pour chaque hashtag. Glissez-déposez le composant « tNormalize » et liez-le au composant tFilterRow en sélectionnant Row > filtre. Configurez le composant tNormalize en sélectionnant la colonne à normaliser (hashtags) et en indiquant le caractère de séparation ( ‘’;’’).

Pour terminer, on inscrit la table normalisée dans un fichier excel à l’aide du composant tFileOutputExcel. Liez le composant tMap à tFileOutputExcel en sélectionnant row > Main. Précisez le chemin d’accès à votre fichier Excel dans lequel vous souhaitez inscrire les données. Cochez aussi la case « Inclure l’en-tête ».
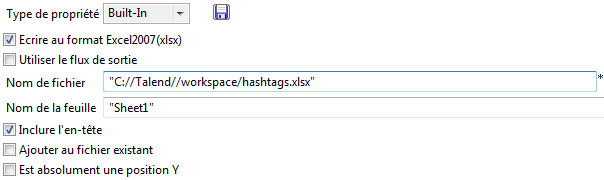
Testez votre job en cliquant sur le bouton « Play ». Si tout fonctionne correctement, répéter la procédure pour construire les listes d’URLs et de mentions.
Une fois que tout est fonctionnel, augmentez la limite de requête pour constituer votre dataset (vous pouvez monter jusqu’à 17.999 messages dans ce scénario).
Nous montrerons dans un second tutoriel quelles analyses peuvent être menées à partir des 4 fichiers Excel que nous venons de constituer.
29 réponses sur « Tutoriel – Utiliser l’API Twitter pour collecter des tweets avec Talend (et sans coder !) »
[…] avons expliqué précédemment comment collecter des tweets. Il peut être intéressant de « découper » ces messages en mots afin de […]
Bonjour,
Tout d’abord, excellent tuto, merci beaucoup. Très clair, tout fonctionne du premier coup, c’est parfait.
Enfin tout ou presque. Je récupère bien les données que je souhaite, mais la recherche s’arrête au bout de moins de 2000 tweets (ce qui représente un peu plus d’une semaine) alors que j’ai bien passé la limite à plus de 10000 comme indiqué à la fin.
Avez-vous déjà rencontré ce problème ?
Merci d’avance,
Clément
Il s’agit des limites de l’api Twitter.vous pouvez récupérer 18000 tweets dans la limite de 7jours. Votre requête retourne donc les 2000 tweets postés au cours de cette période
Bonjour,
Merci pour le Tuto
S’il vous plait j’ai un problème lors de l’ajout des composants twitter.
le message renvoyé c’est que : » Progress Information: Ne répond pas » et aucun composant ne s’affiche
est ce que vous pouvez m’aider
merci d’avance
bonjour dhouha ,
j’ai le même problème lors de l’ajout de composant Twitter , svp pouvez m’aider !
merci d’avance
Bonjour,
s’il vous plait mon second problème réside au niveau du lien entre tFileOutputExcel et tMap. aprés un clic droit sur tMap, je sélectionne row mais je trouve seulement out 2,3 et 4 . Je trouve pas le out1 pour faire le matching ?
Une réponse s’il vous plait
Merci d’avance
vous avez su comment ou pas encore ??
Merci beaucoup pour ce tutoriel! Simple et efficace…
Sinon, petite question: est il possible de requêter sur d’autres champs que celui du contenu des tweets?
Encore merci
Oui. On peut utiliser la librairie twitter4j et exécuter un script java dans un composant tjava
« Cliquez bouton droit sur le composant tMap et liez-le au composant tFileOutputExcel en sélection row > out1 » . En fait ca nous donne pas le choix soit out2 ou out3 ou out4 !
Comment faire svp?
Bonjour,
Si j’ai bien compris , nous ne pouvons récupérer que 18 000 Tweets maximum par requête, du coup comment fait-on si on veut récupérer plus ? Ce nombre de 18 000 est fixé par Talend ou par Twitter.
Effectivement, il n’est pas possible de récupérer plus de 18K tweets à partir de l’API search de Twitter. Il s’agit d’une limitation de Twitter (cf : https://dev.twitter.com/rest/public/search). L’API Streaming est moins restrictive (on peut facilement collecter des millions de messages), en revanche on ne récupère pas de données historiques.
Merci pour votre réponse !
Si je comprends bien, avec l’API Rest on recupère au maximum 18K tweets et avec API Streaming c’est des millions de messages.
Mais deux point restent encore flou pour moi :
1) Que représentent les données historiques dans ce cas ? est ce sont les tweets qui datent plus du délais de temps défini ( ex : 1 semaine ) ?
2) L’API Streaming permet de récupérer les tweets à l’instant présent , est bien cela ? Vous parlez d’un instant t dans l’explication de cet API mais t pourrait s’agir de l’an dernier donc il s’agit des données historiques aussi
Je vous remercie d’avance
Bonjour, Je vous remercie de votre travail.
J’ai un problème au niveau de l’exécution, des erreurs ont été trouvé, voici le résultat :
Démarrage du job twitter a 13:08 23/05/2017.
[statistics] connecting to socket on port 3750
[statistics] connected
Twitter search performed in 0,143000 seconds, tweets found 100 (100 so far, 0 to go)
Twitter search completed – tweets found: 100
Exception in component tTwitterInput_1
java.lang.ClassCastException: java.lang.Boolean cannot be cast to java.lang.String
at twitter28.twitter_0_1.twitter.tTwitterInput_1Process(twitter.java:2415)
at twitter28.twitter_0_1.twitter.tTwitterOAuth_1Process(twitter.java:507)
at twitter28.twitter_0_1.twitter.runJobInTOS(twitter.java:3267)
at twitter28.twitter_0_1.twitter.main(twitter.java:3102)
4282 milliseconds
[statistics] disconnected
Job twitter terminé à 13:08 23/05/2017. [Code sortie=1]
J’ai pas de connaissances en Java, si vous pouvez m’aider ça sera aimable de votre part.
Merci pour votre travail une nouvelle fois.
Bonjour j’ai le même problème que vous. Sauf que chez moi c’est ceci:
Démarrage du job rest a 17:44 30/05/2017.
[statistics] connecting to socket on port 3875
[statistics] connected
Twitter search performed in 0,026000 seconds, tweets found 0 (0 so far, 1000 to go)
Twitter search completed – tweets found: 0
Exception in component tTwitterOAuthClose_1 (rest)
java.lang.NullPointerException
at collecte_tweets.rest_0_1.rest.tTwitterOAuthClose_1Process(rest.java:5882)
at collecte_tweets.rest_0_1.rest.tTwitterInput_1Process(rest.java:5689)
at collecte_tweets.rest_0_1.rest.tTwitterOAuth_1Process(rest.java:585)
at collecte_tweets.rest_0_1.rest.runJobInTOS(rest.java:6152)
at collecte_tweets.rest_0_1.rest.main(rest.java:5971)
[statistics] disconnected
Job rest terminé à 17:44 30/05/2017. [Code sortie=1]
Bonjour j’ai le même problème que vous. Sauf que chez moi c’est ceci:
Démarrage du job rest a 17:44 30/05/2017.
[statistics] connecting to socket on port 3875
[statistics] connected
Twitter search performed in 0,026000 seconds, tweets found 0 (0 so far, 1000 to go)
Twitter search completed – tweets found: 0
Exception in component tTwitterOAuthClose_1 (rest)
java.lang.NullPointerException
at collecte_tweets.rest_0_1.rest.tTwitterOAuthClose_1Process(rest.java:5882)
at collecte_tweets.rest_0_1.rest.tTwitterInput_1Process(rest.java:5689)
at collecte_tweets.rest_0_1.rest.tTwitterOAuth_1Process(rest.java:585)
at collecte_tweets.rest_0_1.rest.runJobInTOS(rest.java:6152)
at collecte_tweets.rest_0_1.rest.main(rest.java:5971)
[statistics] disconnected
Job rest terminé à 17:44 30/05/2017. [Code sortie=1]
Si vous pouvez m’aider,je vous serais reconnaissante. Merci
Bonjour,
Difficile de savoir à partir du log, mais soit votre requête n’a tout simplement pas trouvé de tweets correspondant. Soit vous avez mal configuré le composant tTwitterOauthClose
Bonjour Samuel, je suppose que vous avez mal configuré le composant tTwitterInput ou bien sa sortie. A priori le message d’erreur indique que vous transformez un résultat booléen en chaine de caractère (string)
java.lang.ClassCastException: java.lang.Boolean cannot be cast to java.lang.String
Bonjour,
Merci pour ce tutoriel.
Toutefois, j’ai un soucis avec le composant Twitter OAuth Close, à savoir « la valeur du paramètre (Select a connection to close) n’existe pas ».
Il me semble que cela m’empêche de récupérer les tweets !
Merci d’avance pour votre réponse.
bonjour
merci pour le tutoriel
je veux savoir comment je peux exporter les 4 fichiers excel pour les exploiter sachant que j’ai réussi toutes les étapes
merci pour votre réponse.
Bonjour,
Merci pour ce tuto que j’utilise depuis plus d’un an.
J’ai une question concernant le nombre de caractères des tweets. J’ai bien configuré 220 dans la colonne « lenght » (et j’ai même testé plus), mais la longueur du texte des tweets s’arrête toujours à 140 caractères. Ce qui est dommage car cela coupe mes tweets, qui maintenant sont en plus passés à 280 caractères max.
Avez-vous une idée pour régler mon problème ?
Merci d’avance.
Avec mes meilleurs messages,
Bonjour,
Effectivement, les composants tTwitterOauth et tTwitterInput développés par Gabriele Baldassarre (https://gabrielebaldassarre.com/) ne semblent pas à jour. Apparemment, lors de l’authentification à Twitter, il faut ajouter un paramètre supplémentaire activant l’accès à des données étendues. En java, cela donne :
twitter4j.conf.ConfigurationBuilder()
.setOAuthConsumerKey(« »))
.setOAuthConsumerSecret(« »)
.setOAuthAccessToken(« »)
.setOAuthAccessTokenSecret(« »)
.setTweetModeExtended(true)
Essayez de contacter Gabriele pour voir s’il peut mettre à jour ses composants et tenez-moi au courant… De mon côté, je vais regarder s’il existe des alternatives.
Bonjour et merci pour ce tutoriel, malheureusement je n’arrive pas à télécharger les modules de Gabriele Baldasarre. Le lien ne s’ouvre pas. Auriez-vous une version de ces modules à m’envoyer s’il vous plait ?
Merci beaucoup
Bonjour et merci pour ce tutoriel, malheureusement j’ai le même problème que vous . Je n’arrive pas à télécharger les modules de Gabriele Baldasarre. Le lien ne s’ouvre pas. Pouvez vous m’envoyer les modules s’il vous plaît .
Merci beaucoup
I want to add new component developed by Gabriele Baldassarre but I have a problem I can’t see it in the palette and progress information don’t respond.
je kiffe thanks pour le billet
super le blog j’adore l article, bien documente et instructif
Bonjour .j’ai trouvé les composants de gabriele sur github ( Le lien indiqué ne s’ouvre pas) mais les composants ne s’affiche pas sur la palette
vous pouvez m’aidez svp?
Merci
[…] Talend […]